Choosing the Right AI Models Is Hard. Here’s How to Get It Right.
Large Language Models (LLMs) are evolving fast and for enterprise leaders, the pressure to pick the right ones has never been higher. As more vendors and architectures flood the market, what used to be a simple API call is now a strategic decision with real implications for cost, capability, and customer experience.
At Cloudforce, we’ve spent time building a defensible, repeatable framework to help our clients navigate this complexity. Because the reality is: most companies are struggling to achieve value from generative AI.
Why Most AI Initiatives Stall Out

A recent industry benchmark found 74% of companies struggle to achieve and scale value from their AI investments. And it’s not due to a lack of tools.
The real reasons are more systemic:
- Fragmented AI strategies – Teams adopt tools in isolation, without coordination or alignment to a broader enterprise roadmap.
- Siloed experimentation – DIY and open-source accelerators are used outside core architecture, resulting in brittle, non-scalable builds that stall before production.
- Misplaced trust – Prototypes move forward without validating security, compliance, or governance—leading to late-stage blockers and rework.
- Wasted token spend – Inefficient prompting and verbose outputs bloat API usage and cost.
- Model mismatch – Hype and marketing drive model selection rather than fit-for-purpose evaluation based on operational needs.
- Capability ≠ Reliability – Without rigorous benchmarking, performance assumptions remain unverified and can have misleading results.
The Real Problem?
These aren’t technology problems. They’re alignment, evaluation, and implementation problems. That’s where Cloudforce comes in.
Our Approach: A Repeatable Framework for Model Selection
At Cloudforce, we apply a structured evaluation process to ensure models fit real use cases and scale over time. Our framework includes four key stages:
- Model Intake Management
We continuously track new model releases from leading providers like OpenAI, Anthropic, Meta, and Mistral, building a prioritized inventory aligned to client demand.
- Benchmarking Execution
Using standardized, version-controlled prompts, we rigorously test models across multiple dimensions in an automated and repeatable process.
- Model Recommendations
We normalize and score model performance in a normalized leaderboard format, enabling better business decisions.
- Client Enablement
Our team delivers quarterly briefings that include configuration tips, top-performers, and strategic guidance, keeping your AI stack current and aligned.
What We Measure: The 8 Dimensions of Effective AI
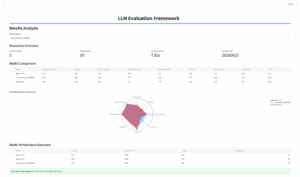
Every model we evaluate is tested across a standardized set of eight criteria:
- Token Efficiency – Cost ($) per response.
- Latency Benchmarks – Time to response.
- Hallucination Rate – Rate of unsupported or incorrect outputs.
- Relevancy – How well the response aligns with the prompt.
- Completeness – Does the answer fully address the question?
- Conciseness – Informative without being verbose.
- Adaptability – Can it follow new instructions or formats?
- Consistency – Reliable behavior across similar prompts.
By comparing models across these dimensions, we ensure tradeoffs are known and intentional.
Why Clients Trust Cloudforce
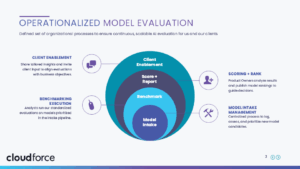
We designed our framework to be:
- Independent – We’re provider-agnostic, benchmarking across all major platforms.
- Pragmatic – We focus on real operational use cases, not theoretical demos.
- Scalable – Our system works for both pilots and enterprise-wide rollouts.
- Secure & Nimble – We move fast, without compromising on governance or quality.
At Cloudforce, we’re helping organizations of all sizes make better AI decisions with confidence, speed, and clarity. Making sure your AI works as your organization needs it to.
Ready to learn how to bring a defensible AI evaluation framework to your organization?
Get in touch with us here or reach out directly via LinkedIn, we’re here to help.
 by
by 













